This post was generated by an LLM, and updated by me.
Attempting to load documents from my knowledgebase, I was running into a wall occasionally and inconsistently – sometimes I would make it through 70% of the db, while other times it would not load the second document. Albeit, I was also having trouble with the embedding method I was using, so the waters were a little muddied at the time. After figuring out the issue with the embeddings, I was more able to focus on what the actual heck was going on with varchar vals I had no control over. I assumed this would all be handled by the vector loader tool… but this was the error I was seeing:
length of varchar field langchain_text exceeds max length
~
length of varchar field loc exceeds max length
I think this person had the same issue: https://github.com/n8n-io/n8n/issues/14563
Here is a blog about it.
When working with Milvus within N8N, users may encounter challenges related to the maximum length of VARCHAR field types, particularly when handling large texts such text chunks from documents. This issue is commonly observed in scenarios where data being inserted into a via the vector loader, lengths are set based on first documents that are loaded – and subsequent document loading may fail due to the low limits automatically assigned when the collection was initialised.
Understanding VARCHAR Field Limitations
In MySQL, for instance (as referenced across several sources), VARCHAR types have strict size limitations ranging between 0 and 65,349 characters [2]. However in the context of Milvus which supports various data formats including text fields used by LangChain applications there are specific constraints too.
Addressing the Issue
After having a think about it, I checked out the docs to see what extra info I could see in relation to the collections I was creating:
POST: http://{{milvus_url}}/v2/vectordb/collections/describe
JSON_BODY: {
"collectionName": "my_docs"
}I could indeed see that the max_lengh of some of the fields was quite low for what I was intending to add. The fact that I was seeing a max length of a ‘loc’ variable, which describes the location of where some text appears within the full text body – meant that it wasn’t just that I was trying to overload the db with too much data.
Addressing the Limitations
Options:
1. Splitting Long Strings – Breaking down long strings into smaller segments before storing them. This can be done via custom logic prior insertion or leveraging existing split functions provided by libraries like LangChain itself, using the recursive loader to split the text into smaller chunks. The issue with this method, was no matter how small I made the chunks, I ended up hitting this error.
2. Use the Milvus RESTful API to load data – Defining the collection manually by using the HTTP nodes in N8N was an option, but recreating the entire data splitter/loader and making sure the meta fields were created correctly for every workflow doesn’t seem like a great way to spend time.
3. Use the Milvus Node, with an HTTP util – I created a subflow to use the Milvus RESTFul API to adjust the fields on the fly. I run this after initialising the collection (of course) – the collection needs to exist with the metafields already set. The fields that I had trouble with are set in a SET VAR node as an array. Here’s a link to the sub-flow you can use if you need it.
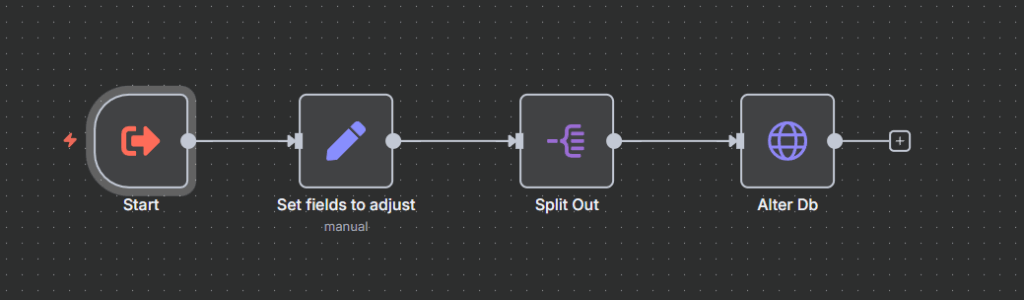
https://gist.github.com/defmans7/c9d9b72e76287572b17df83ee458d0dc
It’s basic, but I wanted to share with anyone that was in the same boat as me, before I moved on to solve other problems. Some ideas for improvement:
- define different field lengths for each field
- add fields to the Start node, so they can be defined in the parent flow
Conclusion
Dealing with limitations around string lengths in databases like Milvus requires careful planning and understanding both the capabilities offered by each system involved along side any direct integration specifics. By either adjusting schema definitions appropriately or employing techniques such as splitting data prior insertion you can effectively manage large text inputs while adhering to technical constraints imposed upon your chosen technologies.
Ideally, the N8N Milvus node should handle this – handle the error and adjust the varchar length dynamically within sensible parameters, in the meantime this is where we’re at.
- https://github.com/hwchase17/langchainjs/issues/2179
- https://community.n8n.io/t/milvus-vector-store-when-create-collection-can-i-set-the-type-of-langchain-text/128885
- https://github.com/milvus-io/milvus/discussions/34478
- https://python.langchain.com/docs/integrations/vectorstores/milvus/
- https://www.atlassian.com/data/databases/understanding-strorage-sizes-for-mysql-text-data-types
- https://www.cpanel.net/blog/products/varchar-vs-text-for-mysql-databases/
- https://github.com/milvus-io/milvus/issues/25580
- https://github.com/milvus-io/milvus/issues/25138
- https://dba.stackexchange.com/questions/334516/why-is-the-data-in-a-varchar-field-exceeding-the-size-limit
- https://github.com/milvus-io/milvus/issues/27470
- https://github.com/milvus-io/milvus/issues/37026
- https://milvus.io/docs/limitations.md
- https://kb.databricks.com/metastore/data-too-long-for-column
- https://api.python.langchain.com/en/latest/_modules/langchain_community/vectorstores/milvus.html
This post has been uploaded to share ideas an explanations to questions I might have, relating to no specific topics in particular. It may not be factually accurate and I may not endorse or agree with the topic or explanation – please contact me if you would like any content taken down and I will comply to all reasonable requests made in good faith.
– Dan
Leave a Reply